Last Updated on April 3, 2026 by Vivekanand
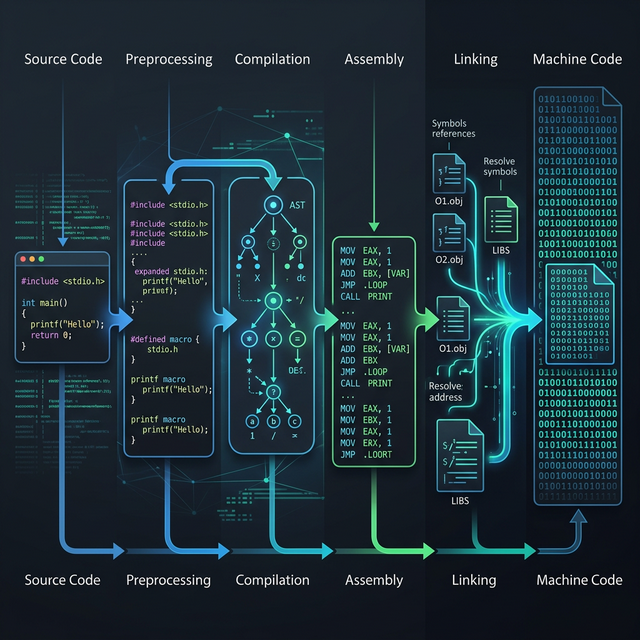
Between your C code and the machine instructions that execute it, there’s a hidden language the compiler invented — and understanding it is the key to understanding how modern compilers actually work. This LLVM IR tutorial will take you inside that language: LLVM’s Intermediate Representation, the universal format that sits between every C function you write and the assembly it becomes.
In Part 2 of this series, we watched the compiler’s frontend transform flat text into a rich Abstract Syntax Tree — the compiler’s understanding of what you wrote. But the AST is still too high-level to optimize or translate directly into machine code. The compiler needs a lower-level representation that’s close enough to hardware to reason about performance, yet abstract enough to work across every target architecture. That representation is LLVM IR — and by the end of this LLVM IR tutorial, you’ll be able to read it, understand it, and generate it yourself with a single Clang command.
Table of Contents
Why Not Go Directly from C to Assembly?
Before diving into LLVM IR itself, let’s understand why compilers use an intermediate representation at all. Why not translate C directly into x86-64 or ARM64 assembly?
The answer is the N × M problem. If you have N source languages (C, C++, Rust, Swift) and M target architectures (x86-64, ARM64, RISC-V, WebAssembly), a direct translation approach would require N × M separate compilers. With 4 languages and 4 targets, that’s 16 compilers to write and maintain.
Without IR (N × M problem):
C ──────────→ x86-64
C ──────────→ ARM64
C ──────────→ RISC-V
C++ ─────────→ x86-64
C++ ─────────→ ARM64
C++ ─────────→ RISC-V
Rust ────────→ x86-64
Rust ────────→ ARM64
... (N × M = explosion)
With IR (N + M solution):
C ────┐ ┌──→ x86-64
C++ ──┤ ├──→ ARM64
Rust ─┤──→ LLVM IR ──→├──→ RISC-V
Swift ┘ └──→ WebAssembly
4 frontends + 4 backends = 8 components instead of 16An intermediate representation breaks the problem into N + M: N frontends that lower source languages to IR, and M backends that lower IR to machine code. Every optimisation pass written against the IR benefits all languages and all targets simultaneously. This is LLVM’s core insight, and it’s why the same optimisation infrastructure powers C, Rust, Swift, and dozens of other languages — they all share the same IR.
LLVM IR Tutorial: The Fundamentals
LLVM IR is a strongly-typed, Static Single Assignment (SSA) based representation that looks like a cross between assembly language and a typed programming language. Let’s break that down piece by piece.
The Type System
Unlike assembly, where everything is just bytes in registers, LLVM IR has explicit types for every value. Here are the most common ones:
| LLVM IR Type | Meaning | C Equivalent |
|---|---|---|
i1 | 1-bit integer (boolean) | _Bool |
i8 | 8-bit integer | char |
i32 | 32-bit integer | int |
i64 | 64-bit integer | long (on 64-bit) |
float | 32-bit IEEE floating point | float |
double | 64-bit IEEE floating point | double |
ptr | Opaque pointer | Any pointer type |
void | No return value | void |
Notice how integers specify their exact bit width — i32, not just “int.” This removes the ambiguity that plagues C, where int might be 16 or 32 bits depending on the platform. In LLVM IR, types are precise and platform-independent.
Naming Conventions
LLVM IR uses two prefixes to distinguish scope:
@name— Global symbols: functions, global variables. These are visible across modules.%name— Local values: registers, labels, local variables. These exist only within a function.
Local values with numeric names like %0, %1, %2 are unnamed temporaries — results of instructions that the compiler generated but didn’t bother naming. Named locals like %a.addr or %sum correspond to variables you declared in your source code.
Static Single Assignment (SSA)
The most important concept in this LLVM IR tutorial is SSA form. In SSA, every variable is assigned exactly once. You can never reassign a value — instead, you create a new variable. This might seem restrictive, but it’s what makes optimization passes efficient: if every value has exactly one definition, data-flow analysis becomes trivial.
Here’s what SSA looks like in practice:
; NOT valid SSA — %x is assigned twice:
%x = add i32 %a, %b
%x = mul i32 %x, 2 ; ERROR: redefinition of %x
; Valid SSA — each value assigned once:
%x = add i32 %a, %b
%y = mul i32 %x, 2 ; New name, no conflictThis restriction means every use of a value can be traced back to exactly one definition, which is extraordinarily powerful for optimization. We’ll see how the compiler handles cases where SSA seems impossible — like loops and conditionals — when we discuss PHI nodes later in this tutorial.
Anatomy of an LLVM IR Function
Let’s see real LLVM IR. We’ll use the same add function from Parts 1 and 2 of this series:
// add.c
int add(int a, int b) {
return a + b;
}Generate the IR with:
# Generate human-readable LLVM IR
clang -S -emit-llvm -O0 add.c -o add.llHere’s the output (cleaned up, with module-level metadata removed for clarity):
define i32 @add(i32 %a, i32 %b) {
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, ptr %a.addr, align 4
store i32 %b, ptr %b.addr, align 4
%0 = load i32, ptr %a.addr, align 4
%1 = load i32, ptr %b.addr, align 4
%add = add nsw i32 %0, %1
ret i32 %add
}Let’s walk through every line of this LLVM IR tutorial example:
| LLVM IR Line | What It Does |
|---|---|
define i32 @add(i32 %a, i32 %b) | Defines a function @add returning i32, taking two i32 arguments |
entry: | Label for the first basic block — the entry point of the function |
%a.addr = alloca i32, align 4 | Allocates 4 bytes on the stack for a copy of parameter a |
store i32 %a, ptr %a.addr | Copies the parameter value into the stack slot |
%0 = load i32, ptr %a.addr | Loads the value back from the stack into register %0 |
%add = add nsw i32 %0, %1 | Adds the two loaded values; nsw = “no signed wrap” (undefined on overflow) |
ret i32 %add | Returns the result |
You might be thinking: “Why all the alloca, store, and load instructions just to add two numbers?” That’s because we compiled with -O0 (no optimization). The frontend generates this verbose pattern by default — every variable gets a stack slot and every access goes through memory. This is correct but slow. We’ll see how the mem2reg optimization pass eliminates this overhead shortly.
The alloca / load / store Pattern
At -O0, Clang uses a simple strategy: allocate a stack slot for every variable and access it through memory. This avoids needing to construct SSA form in the frontend — a significant simplification. The mem2reg optimization pass then promotes these memory accesses into clean SSA registers.
Here’s what our add function looks like after mem2reg (equivalent to compiling with -O1 or higher):
define i32 @add(i32 %a, i32 %b) {
entry:
%add = add nsw i32 %a, %b
ret i32 %add
}That’s it — two instructions instead of seven. The alloca, store, and load instructions are gone. The parameters %a and %b are used directly as SSA values. This is what clean LLVM IR looks like, and it maps almost directly to the final assembly. You can see both versions live on https://godbolt.org/z/Wc7Eeh6bj.
Basic Blocks and Control Flow in LLVM IR
In the add function, we had a single basic block labeled entry:. But real programs have conditionals and loops, which means multiple basic blocks connected by branches. Let’s see this with our max function from Part 2:
// max.c
int max(int a, int b) {
if (a > b)
return a;
return b;
}The optimized LLVM IR (compiled with clang -S -emit-llvm -O1):
define i32 @max(i32 %a, i32 %b) {
entry:
%cmp = icmp sgt i32 %a, %b ; signed greater-than comparison
br i1 %cmp, label %if.then, label %if.end
if.then: ; basic block: a > b is true
br label %if.end
if.end: ; basic block: merge point
%retval = phi i32 [ %a, %if.then ], [ %b, %entry ]
ret i32 %retval
}Now we have three basic blocks — entry, if.then, and if.end — connected by branch instructions. Let’s break down the new instructions:
icmp sgt i32 %a, %b— Integer comparison, signed greater-than. Returnsi1(a boolean).br i1 %cmp, label %if.then, label %if.end— Conditional branch. If%cmpis true, jump to%if.then; otherwise, jump to%if.end.phi i32 [ %a, %if.then ], [ %b, %entry ]— The PHI node. This is where SSA gets interesting.
Every basic block must end with exactly one terminator instruction — either br (branch), ret (return), switch, or unreachable. This rule is what makes LLVM IR’s control flow graph well-defined and analyzable.
PHI Nodes: The Heart of SSA
The phi instruction is the most confusing part of LLVM IR for newcomers, but it’s also the most elegant. The problem it solves: in SSA form, every value is assigned once. But at a merge point in control flow, the value of a variable depends on which path execution took. The PHI node resolves this by saying: “My value is %a if control came from %if.then, or %b if control came from %entry.”
; PHI node syntax:
%result = phi i32 [ value_if_from_block_A, %block_A ],
[ value_if_from_block_B, %block_B ]PHI nodes only appear at the beginning of a basic block, and they “magically” select the right value based on which predecessor block just executed. In hardware, there’s no PHI instruction — the backend lowers PHI nodes into register moves along each edge of the control flow graph.
To see PHI nodes in a more complex scenario, let’s look at a loop. The Fibonacci function is a perfect example because the loop variable changes on every iteration — something that seems impossible under SSA’s “assign once” rule:
// fib.c
int fibonacci(int n) {
int a = 0, b = 1;
for (int i = 0; i < n; i++) {
int temp = a + b;
a = b;
b = temp;
}
return a;
}The optimized LLVM IR (clang -S -emit-llvm -O1):
define i32 @fibonacci(i32 %n) {
entry:
%cmp = icmp sgt i32 %n, 0
br i1 %cmp, label %for.body, label %for.end
for.body: ; loop body
%i = phi i32 [ 0, %entry ], [ %inc, %for.body ]
%a = phi i32 [ 0, %entry ], [ %b, %for.body ]
%b = phi i32 [ 1, %entry ], [ %add, %for.body ]
%add = add nsw i32 %a, %b ; temp = a + b
%inc = add nsw i32 %i, 1 ; i++
%exitcond = icmp eq i32 %inc, %n ; i < n?
br i1 %exitcond, label %for.end, label %for.body
for.end: ; after loop
%result = phi i32 [ 0, %entry ], [ %a, %for.body ]
ret i32 %result
}Look at the three PHI nodes at the top of for.body. Each one says: “On the first iteration (coming from %entry), use the initial value. On subsequent iterations (coming from %for.body — the loop back-edge), use the updated value.” This is how SSA represents mutable variables without mutation — the PHI node creates a new version of the value on each iteration.
You can explore this Fibonacci example interactively on Godbolt Compiler Explorer — toggle between -O0 and -O1 to see the alloca pattern transform into clean PHI nodes.
LLVM IR vs Assembly: Side-by-Side
One of the most illuminating exercises in any LLVM IR tutorial is comparing the IR directly with the assembly it produces. Let’s trace our add function through all three levels:
| C Source | LLVM IR (Optimized) | x86-64 Assembly | ARM64 Assembly |
|---|---|---|---|
int add(int a, int b) | define i32 @add(i32 %a, i32 %b) | add: | add: |
return a + b; | %add = add nsw i32 %a, %b | lea eax, [rdi+rsi] | add w0, w0, w1 |
} | ret i32 %add | ret | ret |
The mapping is remarkably direct. The LLVM IR add nsw i32 instruction doesn’t specify which register to use or which specific machine instruction to emit — that’s the backend’s job. Notice how x86-64 uses lea (load effective address) for the addition while ARM64 uses a straightforward add. The IR is identical for both targets; only the backend differs. This is the power of an intermediate representation.
This also connects directly to what we explored in the Calling Conventions post from the Assembly series — the IR’s %a and %b parameters get mapped to edi/esi (System V ABI) on x86-64 and w0/w1 (AAPCS64) on ARM64 during code generation.
LLVM IR Tutorial: Hands-On Commands
Here’s a complete hands-on session you can run on any system with Clang installed. These commands let you see every intermediate step:
# Create a test file
cat > example.c <<'EOF'
int max(int a, int b) {
if (a > b)
return a;
return b;
}
EOF
# Generate LLVM IR (unoptimized — see the alloca/load/store pattern)
clang -S -emit-llvm -O0 example.c -o example_O0.ll
# Generate LLVM IR (optimized — see clean SSA with PHI nodes)
clang -S -emit-llvm -O1 example.c -o example_O1.ll
# Run a specific optimization pass manually (mem2reg only)
opt -passes=mem2reg -S example_O0.ll -o example_mem2reg.ll
# Compare: IR → x86-64 assembly
clang -S -O1 example.c -o example_x86.s
# Compare: IR → ARM64 assembly (cross-compile)
clang -S -O1 --target=aarch64-linux-gnu example.c -o example_arm.sThe opt tool is LLVM’s standalone optimization tool — it takes IR as input, runs specific passes, and outputs transformed IR. Running opt -passes=mem2reg lets you see exactly how the verbose -O0 output gets cleaned into SSA form, without any other optimizations applied. This is invaluable for understanding what each optimization pass does — a topic we’ll explore in depth in Part 4.
Key LLVM IR Instructions Reference
Here’s a quick reference of the most common LLVM IR instructions you’ll encounter when reading compiler output. For the complete specification, see the LLVM Language Reference Manual.
| Category | Instruction | Description |
|---|---|---|
| Arithmetic | add, sub, mul, sdiv, udiv | Integer arithmetic (signed/unsigned division) |
| Comparison | icmp, fcmp | Integer/float comparison, returns i1 |
| Memory | alloca, load, store | Stack allocation, memory read, memory write |
| Control Flow | br, ret, switch | Branch, return, multi-way branch |
| SSA | phi | Select value based on predecessor block |
| Conversion | zext, sext, trunc, bitcast | Zero-extend, sign-extend, truncate, reinterpret bits |
| Pointer | getelementptr (GEP) | Calculate pointer offset (structs, arrays) |
| Function | call | Call a function |
The nsw and nuw flags you’ll see on arithmetic instructions stand for “no signed wrap” and “no unsigned wrap.” They tell LLVM that the operation is undefined if it overflows — which gives the optimizer permission to make stronger assumptions. This is one of the ways C’s undefined behavior on signed overflow gets encoded into IR.
How LLVM IR Connects to the Stack Frame
If you’ve read Part 3 of the Assembly series (Stack Frames & Function Prologues), you already know how the stack frame is laid out with push rbp and sub rsp on x86-64. Now you can see where those decisions come from: the IR’s alloca instructions map directly to the stack frame.
Each alloca reserves space in the function’s stack frame. The alignment specifier (align 4) tells the code generator how to pad the allocation. When the backend sees all the alloca instructions in a function, it calculates the total stack frame size and emits the prologue (sub rsp, N) accordingly. Variables that get promoted to registers by mem2reg don’t need stack space at all — which is why optimized code has smaller stack frames.
Why LLVM IR Matters for Optimization
The IR is where the real magic of compilation happens. Every optimization pass you’ve ever benefited from — constant folding, dead code elimination, loop unrolling, inlining, auto-vectorization — operates on LLVM IR, not on the source code or the assembly.
Because IR is both low-level enough to reason about costs (every instruction has a latency) and high-level enough to see patterns (SSA makes data flow explicit), it’s the perfect level for optimization. Consider what the optimizer can see in our Fibonacci IR that it couldn’t see in the C source:
- Data dependencies are explicit — the PHI nodes show exactly which values flow where, making dependency analysis trivial.
- Types are machine-precise —
i32tells the optimizer exactly what operations are valid (e.g., it can’t auto-vectorize mismatched types). - Control flow is a graph — the basic block structure makes loop detection, dead branch elimination, and tail-call optimization straightforward.
- Undefined behavior is encoded — the
nswflags give the optimizer freedom that safe-by-default representations can’t.
In Part 4 of this series, we’ll dive deep into specific optimization passes — watching how -O2 transforms IR step by step, from constant propagation to loop vectorization.
GCC’s Intermediate Representations: GIMPLE and RTL
While this LLVM IR tutorial focuses on LLVM, GCC uses its own intermediate representations. Understanding both helps you appreciate the different design philosophies in modern compilers.
GCC uses three levels of IR, whereas LLVM uses one unified representation. After parsing, GCC’s frontend produces GENERIC — a language-independent tree representation similar to an AST. This is immediately lowered into GIMPLE, GCC’s primary optimization IR. GIMPLE is a three-address code representation in SSA form, conceptually similar to LLVM IR but with important differences. After machine-independent optimizations, GIMPLE is lowered into RTL (Register Transfer Language) for machine-specific optimizations and code generation.
| Aspect | LLVM IR | GCC GIMPLE | GCC RTL |
|---|---|---|---|
| Purpose | All optimizations + code gen input | Machine-independent optimization | Machine-specific optimization |
| SSA Form | Yes, always | Yes (after SSA pass) | No (uses pseudo-registers) |
| Type System | Explicit (i32, ptr) | Retains C-like types | Machine modes (SImode, DImode) |
| Design | Modular, reusable across tools | Tightly coupled to GCC | Low-level, pattern-based |
| Viewing | clang -emit-llvm -S | gcc -fdump-tree-gimple | gcc -fdump-rtl-expand |
Here’s what our add function looks like in GIMPLE:
;; GCC GIMPLE output (gcc -fdump-tree-gimple add.c)
add (int a, int b)
{
int D.2345;
D.2345 = a + b;
return D.2345;
}GIMPLE is more readable than LLVM IR because it retains C-like syntax, but it’s less precise about types and less suitable for use outside of GCC. LLVM IR’s explicit type system and modular design are why it’s become the foundation for so many tools beyond compilation — including static analyzers, JIT compilers, and even GPU shader compilers.
And here’s a glimpse of RTL — the low-level representation where GCC maps GIMPLE operations to specific machine patterns:
;; GCC RTL (simplified) for add on x86-64
(insn (set (reg:SI 87)
(plus:SI (reg:SI 5 di) ; parameter a in %edi
(reg:SI 4 si))) ; parameter b in %esi
(insn (set (reg:SI 0 ax) ; result in %eax
(reg:SI 87)))RTL explicitly names hardware registers (di, si, ax) and uses machine-specific modes (SI = Single Integer = 32-bit). This is the point in GCC’s pipeline where platform-specific decisions get made — analogous to what LLVM does during code generation from its single IR. The key philosophical difference: LLVM performs both machine-independent and machine-dependent optimizations on the same IR, while GCC splits them across GIMPLE and RTL.
What’s Next
In this LLVM IR tutorial, we’ve traced the journey from C source through the compiler’s intermediate representation. You’ve seen how LLVM IR uses SSA form with explicit types and PHI nodes to represent programs in a way that’s both precise and optimizable. You’ve learned to generate and read real IR output, compared -O0 and -O1 output, and understood why an intermediate representation exists at all.
But the IR we’ve seen is still the starting point for optimization. In the next post, we’ll watch the optimizer transform this IR — instruction by instruction, pass by pass — and finally understand what -O2 actually does to your code.
Next up: Part 4 — Compiler Optimization Passes: What -O2 Actually Does
Further Reading
- LLVM Language Reference Manual — The definitive specification for every LLVM IR instruction, type, and attribute
- LLVM Kaleidoscope Tutorial — Build a complete language with an LLVM backend, step by step
- How a C Program Becomes Machine Code — Part 1 of this series, placing IR in the context of the full compilation pipeline
- Compiler Lexer & Parser Demystified — Part 2, covering the AST that feeds into IR generation
- Stack Frames & Function Prologues — How IR’s
allocainstructions map to the physical stack frame layout