Last Updated on April 7, 2026 by Vivekanand
You’ve been there. You write a complex calculation in C, compile it, and it feels a bit sluggish. You open your `Makefile`, add `-O2` to your `CFLAGS`, recompile, and suddenly your program is executing three times faster. But what actually is the compiler doing under the hood? Is it magic? Is it just removing debug symbols?
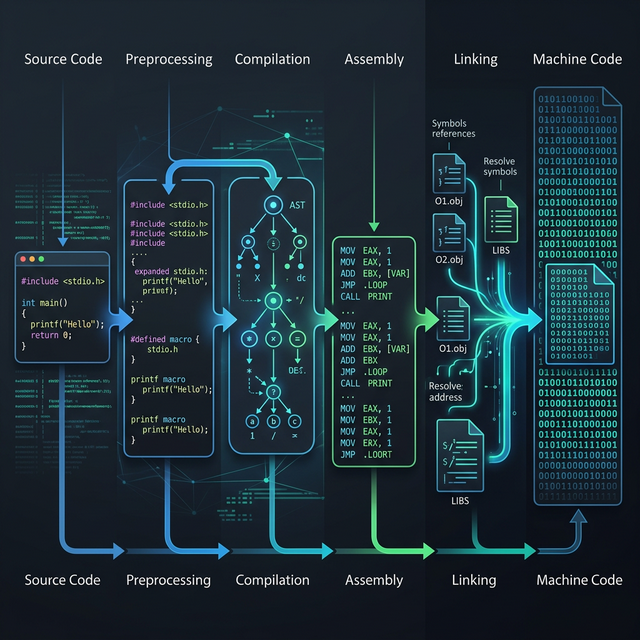
In standard compilation, compiler optimization passes are a gauntlet of transformations that rewrite your source into a mathematically equivalent, but computationally leaner, form. In this part of the Compiler Internals series, we are tearing the lid off the “magic button” that is `-O2`. We’ll trace the exact phases your Intermediate Representation (IR) goes through before it gets emitted as assembly.
Table of Contents
The Optimization Levels: -O0 through -O3
When dealing with GCC or Clang, you’ve likely encountered flags like `-O0`, `-O1`, `-O2`, `-O3`, and `-Os`. Let’s break down the general philosophies:
- -O0 (No Optimization): The default. The compiler’s only goal is to translate your code into machine code as quickly as possible. Every variable read/write goes directly to memory (the stack), which guarantees that your code perfectly matches your source line-by-line. This is vital for debugging but catastrophic for performance.
- -O1 (Basic Optimization): The compiler starts trying to reduce code size and execution time without taking so much compile-time that it becomes annoying. It performs basic register allocation and constant folding but avoids complex transformations.
- -O2 (Standard Optimization): The recommended level for production. The compiler engages the vast majority of its safe optimization passes. It performs aggressive dead code elimination (DCE), common subexpression elimination (CSE), and loop-invariant code motion (LICM). Crucially,
-O2does not perform optimizations that violently increase binary size (like massive loop unrolling). - -O3 (Aggressive Optimization): Turns on all
-O2passes plus heuristics that might trade binary size for performance. Expect aggressive function inlining, greedy loop unrolling, and auto-vectorization (utilizing SIMD instructions like AVX2/AVX-512). Note:-O3can occasionally make code slower due to instruction cache (i-cache) thrashing. - -Os / -Oz (Optimize for Size): Focuses strictly on creating the smallest possible binary. It will often avoid loop unrolling and inlining entirely to save bytes.
Common Machine-Independent Compiler Optimization Passes
These passes operate at the IR level (Intermediate Representation). They don’t care if you’re compiling for an x86-64 server or a tiny ARM64 embedded chip. They simply apply universal laws of computer science to simplify logic. In LLVM, these are Middle-End passes. Let’s look at the cornerstone transformations.
Constant Folding and Propagation
If you write int seconds = 60 * 60 * 24;, the compiler does not emit instructions to multiply 60, 60, and 24 at runtime. It computes 86400 at compile-time. This is Constant Folding. Constant Propagation is the follow-up step: substituting the value of known constants forward into the formulas that use them.
int calculate() {
int a = 10;
int b = 20;
return a + b + 5;
}Under -O2, Clang will output a single x86-64 instruction for this entire function:
# x86-64 assembly (-O2)
calculate:
mov eax, 35
ret(If you want to play with this, check out the Godbolt link: Constant Folding Demo)
Dead Code Elimination (DCE)
If code has no observable side effects (it computes a value that is never used, or resides after a return statement), the compiler ruthlessly deletes it. This is harder than it sounds because the compiler must prove that deleting the code won’t accidentally alter program behavior (e.g., if a discarded function call contained an I/O operation).
Common Subexpression Elimination: Core Compiler Optimization Passes
Why compute something twice when you can compute it once and reuse the value?
// Before CSE
int x = a * b + 10;
int y = a * b + 20;
// After CSE (conceptual)
int tmp = a * b;
int x = tmp + 10;
int y = tmp + 20;This drastically reduces ALU (Arithmetic Logic Unit) strain.
Loop-Invariant Code Motion (LICM)
Loops are where programs spend 90% of their execution time. If a computation inside a loop yields the same result on every single iteration, the compiler “hoists” it outside the loop.
void process(int* arr, int n, int factor) {
for (int i = 0; i < n; i++) {
// factor * 10 is invariant, it never changes inside the loop!
arr[i] = arr[i] + (factor * 10);
}
}The compiler seamlessly evaluates factor * 10 once before the loop begins, holding the result in a register.
These compiler optimization passes ensure that redundant work is moved out of hot loops. Every single one of these compiler optimization passes contributes to the final binary’s efficiency. Another example of such compiler optimization passes is inlining.
Function Inlining
One of the most consequential compiler optimization passes. Jumping to another function incurs severe overhead: pushing arguments, managing the stack frame, branching, and potentially thrashing the instruction cache. Inlining takes the body of a small called function and injects it directly into the caller. This doesn’t just eliminate the call overhead—it exposes the inlined code to further optimizations like CSE and Constant Folding within the caller’s context.
Read more about the cost of function calls in our guide on Calling Conventions.
Machine-Dependent Optimizations
Once the Middle-End has simplified the logic, the compiler Backend takes over. Backend compiler optimization passes are tailored uniquely to the target architecture.
Peephole Optimization
The peephole optimizer looks at a sliding “window” (or peephole) of 2 to 4 generated assembly instructions. If it recognizes an inefficient sequence, it replaces it with a shorter, faster equivalent specific to the CPU.
For example, a compiler might generate the naive instruction to set a register to zero:
mov rax, 0 // Naive (takes 5-7 bytes to encode)The peephole optimizer transforms this into the much faster XOR zeroing idiom:
xor eax, eax // Optimal (takes 2 bytes, breaks dependency chains in superscalar CPUs)Instruction Selection and Auto-Vectorization (SIMD)
Modern CPUs have wide vector registers (like 128-bit XMM registers or 256-bit YMM registers) capable of applying a single operation to multiple data points simultaneously (SIMD).
At -O3 (-O2 in modern compilers), auto-vectorization passes will analyze loops that process arrays. Instead of iterating 100 times to add 100 pairs of integers, the vectorizer might rewrite the loop to process 8 pairs concurrently per cycle, slashing iteration count down to 13.
Peeking Behind the Curtain: Viewing Optimization Passes
If you really want to see the compiler optimize your code step-by-step, you can ask LLVM to print the IR after every single pass executes. It produces a monumental amount of text, but is an incredible learning tool.
clang -mllvm -print-after-all mycode.cYou will see sections detailing the Early CSE pass, followed by the Inliner pass, the Simplify the CFG pass (Control Flow Graph), and heavily involved loop pipelines. It is the ultimate proof that modern compilers are essentially giant graph-manipulation engines.
When Optimizations Go Wrong: The Danger of Undefined Behavior
The golden rule of compiler optimization passes is the “As-if” rule: the compiler can rewrite your code in whatever way it chooses, as long as the observable behavior of the program remains the same.
However, to maximize performance, C and C++ rely heavily on Undefined Behavior (UB). If your code triggers UB (like signed integer overflow or strict aliasing violations), the compiler assumes it never happens. This assumption allows the compiler to mathematically prove that a branch of code is dead, thus erasing it entirely. Sometimes this leads to devastating logic bugs.
Strict Aliasing Rule Violation
The Strict Aliasing Rule states that pointers of different types (e.g., int* and float*) can point to the same memory address, but a violation occurs when dereferencing through an incompatible type. There is one exception though where char* and unsigned char* are explicitly allowed to alias any type.
int fast_inverse(float x) {
int i = *(int*)&x; // STRICT ALIASING VIOLATION (UB)
// The optimization pass might reorder operations here
// because it assumes 'i' and 'x' don't overlap!
return i;
}Compiling with -O2 might introduce erratic bugs here because the Type-Based Alias Analysis (TBAA) pass may reorder memory operations in ways you didn’t expect. If you absolutely must bypass the type system, always use a safely engineered memcpy() (which the compiler understands and will optimize securely) or disable the pass via -fno-strict-aliasing.
Summary
Compiler optimization passes transform your source code into lean, unyielding machine intelligence. From high-level logic trimming via dead code elimination, all the way down to the architecture-specific orchestration of register allocation and SIMD execution, Clang and GCC act as profound layers of abstraction between human thought and the CPU silicon.
Next up, we will dive specifically into how these optimized IR structures get lowered into final machine code in Part 5: Compiler Code Generation.