Last Updated on April 6, 2026 by Vivekanand
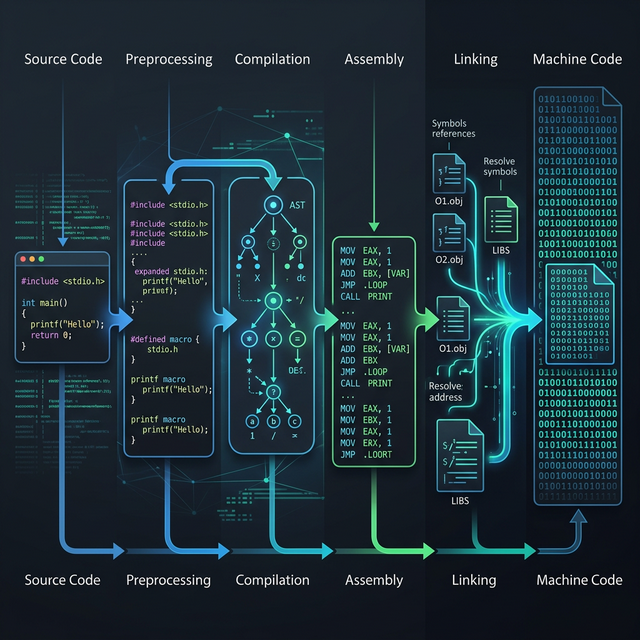
Between the hardware-agnostic world of LLVM Intermediate Representation (IR) and the raw binary bytes your CPU executes lies the backend pipeline—the most platform-specific, meticulously engineered phase of the compiler. In our previous deep dive into LLVM IR, we explored how the compiler represents your logic using an infinite number of virtual registers and generic instructions. But real CPUs are much messier. They have limited registers, pipeline constraints, deep latency considerations, and entirely different Instruction Set Architectures (ISAs).
In this comprehensive guide, we are looking directly into the mechanics of compiler code generation. We will watch the compiler take optimized, platform-independent IR and translate it into hardware-specific x86-64 and ARM64 assembly instructions. If you have ever wondered how a high-level function maps to the specific quirks of silicon, this compiler code generation guide is your roadmap.
Table of Contents
1. The Scope of Compiler Code Generation
When developers hear the phrase “compiler code generation“, they often assume it is a simple 1:1 translation from an abstract syntax tree (AST) or intermediate representation directly to raw assembly language. However, a modern compiler backend is split into multiple highly structured phases. In LLVM, the backend pipeline that handles compiler code generation involves several intermediate states.
The backend accepts optimized LLVM IR (which uses Single Static Assignment, or SSA form) and runs it through target-dependent phases. Here is what happens under the hood during compiler code generation:
- Instruction Selection: Maps IR instructions to machine instructions (MachineInstrs).
- Instruction Scheduling (Pre-RA): Reorders instructions to maximize instruction-level parallelism (ILP) and minimize pipeline stalls, before physical registers are clamped down.
- Register Allocation: Replaces the infinite virtual registers with the CPU’s finite physical registers (e.g., RAX, x0).
- Instruction Scheduling (Post-RA): A second reordering pass, dealing with constraints imposed by the newly assigned physical registers.
- Code Emission: Translates MachineInstrs into raw byte streams (object code) or human-readable `.s` assembly files.
Unlike the frontend, which cares about C or C++ semantics, compiler code generation cares exclusively about latency, throughput, and hardware capabilities. You can read more about LLVM’s official target-independent code generation documentation here.
2. Instruction Selection: Matching Patterns to Hardware
The first major hurdle in compiler code generation is Instruction Selection. How does the compiler know which specific assembly instruction to use for a particular math operation or memory access? CPUs often have dozens of ways to accomplish the same logical operation.
For example, in x86-64, an addition could be performed by the add instruction, the inc instruction (if adding 1), or even hidden inside a lea (Load Effective Address) instruction. Deciding between these is the job of the instruction selector.
The SelectionDAG
Historically, LLVM has used a graph-based representation called the SelectionDAG (Directed Acyclic Graph) for the initial phases of compiler code generation. The intermediate representation is lowered into a giant graph where nodes represent operations (like add, load, store) and edges represent data or control dependencies.
The SelectionDAG goes through several legalization steps. Because LLVM IR allows arbitrary bit-widths (you can literally have an i17—a 17-bit integer), the compiler code generation phase must legalize these types. The DAG Legalizer ensures that any data type not natively supported by the hardware (like a 17-bit integer on a 64-bit architecture) is promoted or split down into legal types (like 32-bit or 64-bit integers).
Pattern Matching
Once the DAG is legal, LLVM uses a complex pattern-matching engine to fold multiple DAG nodes into a single hardware instruction. Let’s look at the classic lea optimization on x86-64.
int calculate_index(int a, int b) {
return a + (b * 4) + 12;
}In LLVM IR, this involves multiple separate instructions: a multiply, an addition, and another addition. However, during compiler code generation for x86-64, the pattern matcher recognizes that all these operations perfectly map onto the addressing mode of an x86 memory instruction. Consequently, the compiler emits a single lea instruction instead of three arithmetic operations.
# x86-64 Output
lea eax, [rdi + rsi*4 + 12]
retOn ARM64, the compiler code generation outcome is completely different, because ARM does not have a monolithic lea instruction that can do shifted addition with an immediate offset in one go. Instead, you’ll see separate add instructions taking advantage of ARM’s flexible shifting capabilities. This ISA divergence is exactly why compiler code generation is incredibly complex!
3. Instruction Scheduling: Hiding CPU Latency
Once we have mapped LLVM nodes to Target-Specific Machine Instructions (MachineInstr), the compiler code generation engine does not simply output them in their original order. To achieve optimal performance, it must rearrange them.
Modern CPUs, from Apple Silicon to AMD Ryzen, are superscalar. They can execute multiple instructions per clock cycle—provided those instructions do not depend on each other. If instruction B needs the result of instruction A, B must wait until A finishes. This creates a pipeline stall. The goal of instruction scheduling is to shuffle the order of instructions to maximize the distance between dependent operations.
Data Hazards and Dependencies
There are three main types of data hazards that constraint how the compiler code generation scheduling algorithms function:
- Read-After-Write (RAW): A true dependency. Instruction 2 requires the value written by Instruction 1.
- Write-After-Read (WAR): An anti-dependency. Instruction 2 overwrites a register currently being read by Instruction 1.
- Write-After-Write (WAW): An output dependency. Both instructions write to the same register, and the final value needs to match the correct program order.
When the compiler code generation scheduler executes, it looks up the specific hardware latency models. For instance, a floating-point division might take 14 cycles, while a bitwise xor takes 1 cycle. The compiler intentionally pulls unrelated instructions and places them immediately after the division. While the CPU’s division unit grinds away for 14 cycles, the integer ALUs can execute the unrelated instructions “for free.”
Consider this Godbolt example snippet compiling on an ARM64 backend:
void process_data(float *arr) {
float x = arr[0] / arr[1]; // Long latency
arr[2] = arr[3] + arr[4]; // Unrelated
arr[5] = x * 2.0f; // Dependent on division
}During the compiler code generation phase, the optimizer will push the independent addition (arr[3] + arr[4]) right between the division and the multiplication. This allows the CPU to overlap execution, practically hiding the cost of the floating-point addition entirely. This pre-register-allocation scheduling is aggressive, aiming to exploit the maximum theoretical parallelism of the target hardware pipeline.
4. Register Allocation Preview: The Infinite to Finite Shift
Until this stage in the compiler code generation pipeline, the compiler pretends it has an infinite amount of hardware registers. In LLVM IR, every result receives a brand-new virtual register names (like %1, %2, etc.). This makes optimization incredibly easy because you don’t have to worry about overwriting data.
But x86-64 only has 16 general-purpose registers (RAX, RBX, RCX, etc., through R15). ARM64 has 31. The Register Allocation phase takes thousands of virtual registers and maps them to these physical resources.
If the compiler code generation backend runs out of physical registers, it must “spill” a register to the stack (RAM). Memory is incredibly slow compared to CPU registers. Therefore, register allocation is mathematically framed as a graph coloring problem, minimizing the number of stack spills to ensure peak performance. We will devote the entirety of Part 6 to the intricate mechanics of Register Allocation.
5. Stack Frame Layout: Prologues and Epilogues
After register allocation, the compiler finally knows exactly how much stack space the current function needs. At this point, the compiler code generation engine performs “Frame Lowering.” It inserts prologue instructions at the start of the function and epilogue instructions at all return points.
If you’ve read Assembly Part 3: Stack Frames, you know that saving caller-saved and callee-saved registers is necessary. This is precisely where that boilerplate assembly is born!
The compiler code generation Frame Lowering pass calculates offsets. If an integer variable was spilled to the stack, the compiler now definitively patches the offset from the base pointer (e.g., [rbp - 16] on x86, or [sp, #16] on ARM64). Additionally, if the function uses a lot of local stack memory, the prologue will modify the stack pointer (sub rsp, 0x40) to reserve the appropriate memory.
By the time Frame Lowering concludes, the code contains all the instructions needed to execute flawlessly at runtime, adhering perfectly to the operating system’s standard Application Binary Interface (ABI)—like the System V ABI for Linux on x86-64, or the AAPCS on ARM.
6. Assembly Emission: Text and Object Files
The final step in compiler code generation is emission. The LLVM MachineInstr representations must finally be turned into text (the familiar .s assembly file you observe with gcc -S) or directly into a stream of raw bytes (an ELF, Mach-O, or PE object file using gcc -c).
LLVM uses the Machine Code (MC) layer to handle emission. The MC framework is essentially an integrated assembler. Instead of printing text assembly out to a file and invoking an external program (like the GNU as assembler), the MC layer allows LLVM to directly encode the instructions down to raw opcodes. It understands that a mov instruction on x86 corresponds to the byte 0x89, alongside the modR/M byte encoding.
During direct object code emission, the compiler code generation pipeline must produce the final section headers (like .text for executable code, and .rodata for strings) and handle unresolved symbols via Relocation Records. If you call an external function like printf, the code generator emits a relocation patch note telling the dynamic linker to resolve it at load time. (Check out Assembly Part 6: Dynamic Linking for an in-depth exploration of relocations!)
Interactive x86-64 AVX2 Example
Interactive ARM64 NEON Example
7. Cross-Platform Compiler Code Generation: A Comparison
To truly grasp the power of the compiler code generation abstraction, let’s look at a concrete Code Generation example. We’ll take a highly optimizable math loop—a vector dot product—and observe how differently the LLVM backend resolves it across architectures.
If we run this through Clang with -O3 optimization, the frontend and the middle-end optimizer generate an intermediate representation showcasing loop unrolling and auto-vectorization into wide SIMD vectors. However, the subsequent compiler code generation output diverges drastically.
x86-64 Output (AVX2)
For an Intel or AMD processor, the compiler code generation target is Advanced Vector Extensions (AVX2). The x86-64 backend emits 256-bit AVX2 vfmadd231ps instructions, completely unrolling the loop to operate on 8 floating-point numbers per cycle.
vmovups ymm1, ymmword ptr [rdi + 4*rcx]
vfmadd231ps ymm0, ymm1, ymmword ptr [rsi + 4*rcx]
add rcx, 8
cmp rcx, rdx
jb .LBB0_4Notice the x86-specific capabilities integrated natively into the instruction: the memory lookup uses scaled addressing ([rdi + 4*rcx]) mapping directly to memory without explicit pointer arithmetic instructions. This is the x86 compiler code generation backend flexing its complex addressing modes.
ARM64 Output (NEON)
When compiling for an ARM-based chip (like the Apple M-series), the compiler code generation pipeline looks totally different. Advanced SIMD (NEON) registers on ARM64 are exclusively 128-bit wide. The ARM64 backend instruction selector maps the vectorized IR onto fmla (Floating-point Multiply-Add) instructions operating on vectors.
ldr q1, [x0, x8, lsl #2]
ldr q2, [x1, x8, lsl #2]
fmla v0.4s, v1.4s, v2.4s
add x8, x8, #4
cmp x8, x2
b.lt .LBB0_4Unlike AVX2, NEON requires explicit memory loads into the q1 and q2 registers via ldr before the floating-point fused-multiply-add takes place. Because ARM is a Reduced Instruction Set Computer (RISC), it prevents instructions from reading memory directly into arithmetic operations. But notice the efficient post-index/shifted addressing (ldr q1, [x0, x8, lsl #2]). The ARM64 compiler code generation pass leverages the specific shifting capabilities built directly into the ARM memory controller to negate overhead.
For a detailed architectural breakdown of this discrepancy, you can try out the cross-platform comparison natively inside Compiler Explorer. Experiencing the distinct behaviors of compiler code generation backends first-hand solidifies how crucial this stage of compilation actually is.
8. Conclusion
The process of compiler code generation solves an extraordinarily difficult mathematical puzzle: translating infinite platform-agnostic assumptions into a finite environment of stringent, real-world physical electronics constraints. The interplay of pattern-matching SelectionDAGs, deeply optimized CPU schedulers, register constraint allocators, and assembly-level Object emitters results in the blazing fast binaries developers rely on every day.
We’ve looked at the major phases behind instruction emission, but deferred diving deeply into the most complex problem of all constraints—allocating physical registers. In Part 6: Register Allocation, we will strip away the magic and dissect the Register Allocation math that ultimately dictates how your data lives inside your CPU.